
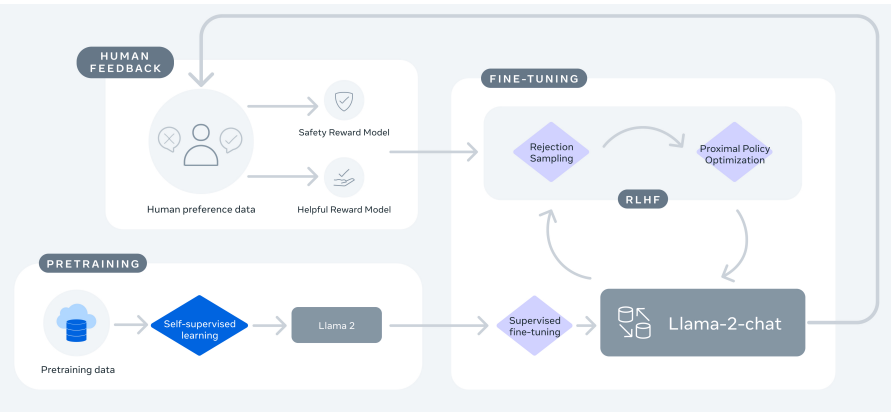
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Llama 2 is a family of pre-trained and fine-tuned large language models LLMs released by Meta AI in 2023 Released free of charge for research and commercial use Llama 2. In this work we develop and release Llama 2 a family of pretrained and fine-tuned LLMs Llama 2 and Llama 2-Chat at scales up to 70B parameters On the series of helpfulness and safety. We release Code Llama a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models infilling capabilities support for large..
Thoughts From Llama 2 Paper Meta Recently Launched Llama 2 By Manav Gupta Medium
All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion tokens and have double the context length of Llama 1. Meta developed and publicly released the Llama 2 family of large language models LLMs a collection of pretrained and fine-tuned generative text models. Just FYI for somebody looking at non-quantized default llama-2-70b-chat model During inference on 8xA100 40GB SXM. Llama 2 comes in a range of parameter sizes 7B 13B and 70B as well as pretrained and fine-tuned variations. Llama 2 - Meta AI This release includes model weights and starting code for pretrained and fine-tuned Llama language models Llama Chat Code Llama..
In this work we develop and release Llama 2 a family of pretrained and fine-tuned LLMs Llama 2 and Llama 2. . We introduce LLaMA a collection of foundation language models ranging from 7B to 65B parameters..
Thoughts From Llama 2 Paper Meta Recently Launched Llama 2 By Manav Gupta Medium
LLaMA-65B and 70B performs optimally when paired with a GPU that has a minimum of 40GB VRAM. More than 48GB VRAM will be needed for 32k context as 16k is the maximum that fits in 2x 4090 2x 24GB see here. Below are the Llama-2 hardware requirements for 4-bit quantization If the 7B Llama-2-13B-German-Assistant-v4-GPTQ model is what youre after. Using llamacpp llama-2-13b-chatggmlv3q4_0bin llama-2-13b-chatggmlv3q8_0bin and llama-2-70b-chatggmlv3q4_0bin from TheBloke MacBook Pro 6-Core Intel Core i7. 1 Backround I would like to run a 70B LLama 2 instance locally not train just run Quantized to 4 bits this is roughly 35GB on HF its actually as..


Comments